
https://github.com/johnny-godoy/laboratorios-mds/blob/main/lab%208/laboratorio_8.ipynb¶GridSearchCountVectorizer.GridSearch.El laboratorio deberá ser desarrollado sin el uso indiscriminado de iteradores nativos de python (aka "for", "while"). La idea es que aprendan a exprimir al máximo las funciones optimizadas que nos entrega pandas, las cuales vale mencionar, son bastante más eficientes que los iteradores nativos sobre DataFrames.
# Librería core del lab.
import numpy as np
import pandas as pd
# Pre-procesamiento
from sklearn.compose import ColumnTransformer
from sklearn.feature_selection import SelectPercentile, chi2
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import LabelEncoder, MaxAbsScaler, MinMaxScaler
# Modelamiento
from sklearn.dummy import DummyClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.naive_bayes import ComplementNB, MultinomialNB
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.svm import SVC
# Evaluación
from sklearn.experimental import enable_halving_search_cv
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.model_selection import GridSearchCV, HalvingGridSearchCV
from sklearn.model_selection import train_test_split
# Librería para plotear
import plotly.express as px
# NLP
import nltk
from nltk import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
nltk.download('stopwords')
nltk.download('punkt')
pd.options.plotting.backend = "plotly"
[nltk_data] Downloading package stopwords to [nltk_data] C:\Users\David\AppData\Roaming\nltk_data... [nltk_data] Package stopwords is already up-to-date! [nltk_data] Downloading package punkt to [nltk_data] C:\Users\David\AppData\Roaming\nltk_data... [nltk_data] Package punkt is already up-to-date!
En vez de estar desarrollando las evaluaciones correspondientes a su curso, su profesor de catedra y su auxiliar discuten acerca la alineación (héroe o villano) del personaje de ficción Bat-Cow.
El cuerpo docente, no logra ponerse de acuerdo si el personaje es bueno, neutral o malo: el auxiliar plantea que Bat-cow posee una siniestra mirada, intrigante pero común característica de los personajes malvados. Por otra parte, extendiendo las ideas de Rousseau, el profesor plantea que tal como los humanos no nacen malos, no existe motivo por el cual una vaca con superpoderes deba serlo.
Sin embargo, ambos concuerdan que es difícil estimar la alineación solo usando los atributos físicos, por lo que creen el análisis debe ser complementado aún más antes de comunicarle los resultados a su estudiantado. Buscando más información, ambos sujetos se percatan de la existencia de un excelente antecedente para estimar la alineación: la historia personal de cada superhéroe o villano.
Es por esto le solicitan que construya y optimice un clasificador basado en texto el cual analice la alineación de cada personaje basado en su historia personal.
Para este laboratorio deben trabajar con los datos df_comics.csv y comics_no_label.csv subidos a u-cursos. El primero es un conjunto de datos que les servirá para entrenar un modelo de clasificación, mientras que el segundo es un dataset con personajes de ficción no etiquetados a predecir (sí, aquí está la misteriosa Batcow).
Para comenzar cargue los dataset señalados y visualice a través de un head los atributos que poseen cada uno de los dataset.
df_comics = pd.read_csv('data/df_comics.csv')
df_comics_no_label = pd.read_csv('data/comics_no_label.csv')
df_comics = df_comics.dropna(subset=['history_text']) # eliminar ejemplos sin historia
# queda a labor de su equipo hacer el análisis exploratorio
df_comics.head()
| Unnamed: 0 | name | real_name | full_name | overall_score | history_text | powers_text | intelligence_score | strength_score | speed_score | ... | has_flight | has_accelerated_healing | has_weapons_master | has_intelligence | has_reflexes | has_super_speed | has_durability | has_stamina | has_agility | has_super_strength | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3-D Man | Delroy Garrett, Jr. | Delroy Garrett, Jr. | 6 | Delroy Garrett, Jr. grew up to become a track ... | NaN | 85 | 30 | 60 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 2 | A-Bomb | Richard Milhouse Jones | Richard Milhouse Jones | 20 | Richard "Rick" Jones was orphaned at a young ... | On rare occasions, and through unusual circu... | 80 | 100 | 80 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 3 | Aa | Aa | NaN | 12 | Aa is one of the more passive members of the P... | NaN | 80 | 50 | 55 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 4 | Aaron Cash | Aaron Cash | Aaron Cash | 5 | Aaron Cash is the head of security at Arkham A... | NaN | 80 | 10 | 25 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 5 | Aayla Secura | Aayla Secura | NaN | 8 | ayla Secura was a Rutian Twi'lek Jedi Knight (... | NaN | 90 | 40 | 45 | ... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
5 rows × 82 columns
Haremos un poco de exploración simple. Primero eliminemos el índice
exploration_df = df_comics.drop("Unnamed: 0", axis=1) # Este df lo modificaremos libremente en exploración
Veamos la distribución de las categorías
fig = px.bar(exploration_df.alignment.value_counts())
fig.update_layout(xaxis_title="Alignment",
yaxis_title="Count",
title="Amount of data per alignment class")
fig
Observamos que el problema de clasificación está desbalanceado. Ahora veamos las features, empezando por las enteras:
exploration_df.select_dtypes("int")
| intelligence_score | strength_score | speed_score | durability_score | power_score | combat_score | |
|---|---|---|---|---|---|---|
| 0 | 85 | 30 | 60 | 60 | 40 | 70 |
| 1 | 80 | 100 | 80 | 100 | 100 | 80 |
| 2 | 80 | 50 | 55 | 45 | 100 | 55 |
| 3 | 80 | 10 | 25 | 40 | 30 | 50 |
| 4 | 90 | 40 | 45 | 55 | 55 | 85 |
| ... | ... | ... | ... | ... | ... | ... |
| 1362 | 90 | 10 | 25 | 30 | 100 | 55 |
| 1363 | 80 | 100 | 100 | 100 | 100 | 80 |
| 1364 | 95 | 50 | 100 | 75 | 100 | 80 |
| 1365 | 75 | 10 | 100 | 30 | 100 | 30 |
| 1366 | 45 | 80 | 75 | 95 | 80 | 50 |
1285 rows × 6 columns
Estos son precisamente los atributos de interés que aparecerán luego. Veamos sus distribuciones
exploration_df.select_dtypes("int").boxplot()
Agrupando ahora por la variable de respuesta
px.box(exploration_df.select_dtypes("int"), color=exploration_df.alignment)
No se ven patrones que permitan una clasificación trivial. Ahora se ven los objetos.
exploration_df.select_dtypes("object").nunique().sort_values(ascending=False)
name 1285 history_text 1274 img 1215 superpowers 1166 first_appearance 1003 real_name 971 powers_text 939 aliases 860 full_name 794 relatives 775 occupation 753 base 519 alter_egos 463 place_of_birth 422 teams 390 weight 242 height 116 overall_score 87 type_race 63 creator 39 hair_color 30 eye_color 25 skin_color 15 alignment 3 gender 2 dtype: int64
Es extraño que el nombre real no sea único: Esto puede ocurrir porque existen varias variantes del mismo personaje (distintas historias). Esto puede causar un sesgo en validación si es que un mismo personaje queda con distintas variantes en distintos splits (dado que en general seguiran alineados de la misma forma), pero por simplicidad ignoraremos esto.
Había realizado más análisis de otras características, pero decidí eliminarlo dado que nos concentraremos solamente en estas durante el laboratorio.

Primero que todo, deben obtener un vector de características del atributo history_text, utilizando Bag of Words. En este atributo se presenta una breve descripción de la historia de cada uno de los personajes de ficción presentes en el dataset.
Pero... antes de empezar, ¿Que es Bag of Words?...
Bag of Words es un modelo de conteo utilizado en Procesamiento de Lenguaje Natural (NLP) que tiene como objetivo generar una representación vectorial (vector de características en nuestro cas) para cada documento a través del conteo de las palabras que contienen.
La siguiente figura muestra un ejemplo de Bag of Words en acción:
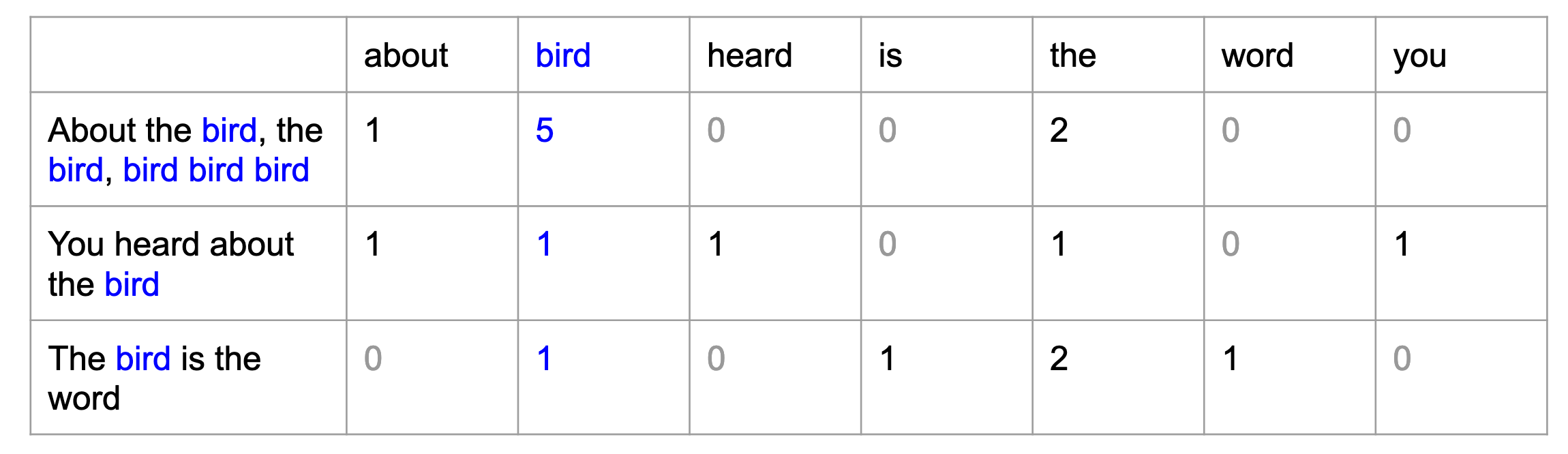
Como pueden ver, el modelo de Bag of Words no resulta tan complicado, ¿pero cómo lo aplicamos en python?.
Como podrán darse cuenta del ejemplo anterior, para facilitar el conteo será necesario transformar cada uno de los documentos en vectores, donde cada una de las posiciones posee un carácter. Este proceso es conocido como tokenización y lo podemos realizar de la siguiente forma:
docs = ['The teacher rocks like a good rock & roll',
'the rock is the best actor in the world']
docs_tokenizados = [word_tokenize(doc) for doc in docs]
docs_tokenizados
[['The', 'teacher', 'rocks', 'like', 'a', 'good', 'rock', '&', 'roll'], ['the', 'rock', 'is', 'the', 'best', 'actor', 'in', 'the', 'world']]
Podemos mejorar un poco más el proceso de tokenización agregando

stop_words = stopwords.words('english') # stopwords.words('spanish')
# Definimos un tokenizador con Stemming
class StemmerTokenizer:
def __init__(self):
self.ps = PorterStemmer()
def __repr__(self):
return f"{self.__class__.__name__}()"
def __call__(self, doc):
doc_tok = word_tokenize(doc)
doc_tok = [t for t in doc_tok if t not in stop_words]
return [self.ps.stem(t) for t in doc_tok]
# Inicializamos tokenizador
tokenizador = StemmerTokenizer()
# Creamos algunos documentos
docs = ['The teacher rocks like a good rock & roll',
'the rock is the best actor in the world',
'New York is a beautiful city']
# Obtenemos el token del primer documento
[tokenizador(doc) for doc in docs]
[['the', 'teacher', 'rock', 'like', 'good', 'rock', '&', 'roll'], ['rock', 'best', 'actor', 'world'], ['new', 'york', 'beauti', 'citi']]
# Comparación con el caso anterior
docs_tokenizados = [word_tokenize(doc) for doc in docs]
docs_tokenizados
[['The', 'teacher', 'rocks', 'like', 'a', 'good', 'rock', '&', 'roll'], ['the', 'rock', 'is', 'the', 'best', 'actor', 'in', 'the', 'world'], ['New', 'York', 'is', 'a', 'beautiful', 'city']]
Scikit implementa bag of words a través de la clase CountVectorizer() la cual contiene muchas opciones para mejorar la tokenización.
bow = CountVectorizer(tokenizer=StemmerTokenizer())
df = bow.fit_transform(docs)
pd.DataFrame(df.toarray(), columns=bow.get_feature_names_out())
| & | actor | beauti | best | citi | good | like | new | rock | roll | teacher | world | york | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 2 | 1 | 1 | 0 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
Una de las cosas más interesantes que provee son el use de n-gramas, los cuales, en palabras simples, son conjuntos de n-palabras que se concatenan entre si y que se consideran como tokens separados.
Pensemos en Nueva York. Cuando se tokeniza Nueva York, se generan dos tokens independientes que a simple vista no tienen relación: Nueva York.
Al usar n-gramas (en un rango min=1,max=2) , generamos tanto Nueva y York como también Nueva York como un token independiente.
bow = CountVectorizer(tokenizer=StemmerTokenizer(), ngram_range=(1,2))
df = bow.fit_transform(docs)
pd.DataFrame(df.toarray(), columns=bow.get_feature_names_out())
| & | & roll | actor | actor world | beauti | beauti citi | best | best actor | citi | good | ... | rock | rock & | rock best | rock like | roll | teacher | teacher rock | world | york | york beauti | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 2 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | ... | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
3 rows × 25 columns
De los resultados, podemos ver que generamos vectores de conteo para cada una de las palabras que conforman el corpus. Un punto extra que se agrega en esta obtención de frecuencias son los bigramas, que básicamente son el conjunto de palabras de tamaño de aparecen juntas en el texto.

Conociendo ahora que es el proceso de bag of words, aplique este modelo de obtención de caracteristicas de la siguiente forma en un pipeline:
bog = CountVectorizer(tokenizer= StemmerTokenizer(),`
ngram_range=(1,2) # Este punto es opcional y es para generar bigramas
)
Finalmente, aplique MinMaxScaler() sobre atributos_de_interes y concatene el valor obtenido con el matriz de caracteristicas obtenidas con bag of words.
atributos_de_interes = ['intelligence_score', 'strength_score', 'speed_score', 'durability_score', 'power_score', 'combat_score']
No es necesario que obtenga un dataframe en concreto con las características solicitadas. Se le recomienda generar un ColumnTransformer() para aplicar las transformaciones solicitadas en un pipeline.
To-Do:
CountVectorizer) caracteristicas del resumen de historia de cada personaje.MinMaxScaler sobre los atributos de interes.Respuesta:
atributos_de_interes = ['intelligence_score', 'strength_score', 'speed_score',
'durability_score', 'power_score', 'combat_score']
transformer = ColumnTransformer([("score_scaler", MinMaxScaler(), atributos_de_interes),
("bag_of_words", CountVectorizer(tokenizer=StemmerTokenizer(), ngram_range=(1,2)), "history_text"),
]
)
De todos modos vale la pena ver el dataframe en concreto resultante

Genere un Pipeline con las caracteristicas solicitadas en la sección 1.1, un selector de mejores features SelectPercentile con métrica f_classif y percentile=90 y un clasificador MultinomialNB() por defecto.
Luego, separe el conjunto de datos en un conjunto de entrenamiento y prueba, donde las etiquetas estará dado por el atributo alignment.
Entrene el modelo y reporte el desempeño con un classification_report. ¿ Nos recomendaría predecir la alineación de BatCow con este clasificador?.
Finalmente, compare el modelo entrenado con un modelo Dummy estratificado y responda: ¿El clasificador entrenado es mejor que el dummy que entrega respuestas al azar?
To-do:
MultinomialNB().classification_report asociado y comentar los resultados.DummyClassifier con estrategia statified, calcular el classification_report asociado y comentar que implican los scores obtenidos en comparación con los resultados del baseline.Respuesta:
Creando el Pipeline
feature_pipeline = make_pipeline(transformer,
SelectPercentile(percentile=90) # default ya es f_classif
)
nb_clf = make_pipeline(feature_pipeline,
MultinomialNB(alpha=.5)
)
Preparando los datos
X = df_comics.drop("alignment", axis=1)
y = df_comics.alignment
Dado el desbalance ya determinado, realizamos el holdout con estratificación.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0,
stratify=y, shuffle=True)
y_testEntrenando el pipeline, y ver el classification_report
y_pred = nb_clf.fit(X_train, y_train).predict(X_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
Bad 0.68 0.25 0.36 108
Good 0.63 0.94 0.76 186
Neutral 0.17 0.04 0.06 28
accuracy 0.63 322
macro avg 0.49 0.41 0.39 322
weighted avg 0.61 0.63 0.57 322
Analizando el desempeño según cada clase:
y_pred = DummyClassifier(strategy="stratified", random_state=0).fit(X_train, y_train).predict(X_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
Bad 0.32 0.30 0.31 108
Good 0.58 0.60 0.59 186
Neutral 0.09 0.11 0.10 28
accuracy 0.45 322
macro avg 0.33 0.33 0.33 322
weighted avg 0.45 0.45 0.45 322
Acá vemos que el desempeño de clasificación del Dummy es peor para los buenos y los malos, tal como se espera, pero vemos que MultinomialNB es peor en clasificar a los personajes neutrales que una estrategia aleatoria. Esto ocurre por el gran desbalance que desfavorece al clasificador, por lo cual preferiremos un clasificador como Complement Naive Bayes

No conformes con el rendimiento obtenido en la sección 1.2, el cuerpo docente les pide que realicen un HalvingGridSearchCV con diferentes parámetros para mejorar el rendimiento de la clasificación. Para esto, se le solicita que defina:
n-gram range del CountVectorizer probando (1,1), (1,2) y (1,3). Examinar también los otros parámetros de CountVectorizer como por ejemplo max_df, min_df, etc... (Documentación aquí)SelectPercentile en los percentiles [20, 40, 60, 80] (puede usar la métrica que usted quiera).A continuación, un ejemplo de parametros para GridSearch para una búsqueda de 3 clasificadores distintos:
params = [
# clasificador 1 + hiperparámetros
{'clf': classificator1(),
'clf__penalty': ['ovr'],
# clasificador 1 + hiperparámetros
{'clf': classificator2(),
'clf__n_estimators': [200]},
# clasificador 1 + hiperparámetros
{'clf': classificator3(),
...
}
]
Nota 1: Puede ver los parámetros modificables aplicando el método get_params() sobre su pipeline. Ver la clase de GridSearch para mayor información sobre la sintáxis de las grillas.
Nota 2: Recuerde inicializar los clasificadores con un random state definido.
Nota 3: Puede usar en HalvingGridSearchCV el parámetro verbose=10 para ver que GridSearch le indique el estado de su ejecución.
Nota 3: El GridSearch puede tomar tiempos de búsqueda exorbitantes, por lo que se le recomienda no agrandar mucho el espacio de búsqueda, dejar corriendo el código y tomarse un tecito.
Respuesta:
Los modelos a elegir se basarán en la guía de sklearn de elección de modelos, que recomienda SVC lineal, Naïve Bayes, SVC rbf y modelos de ensamblaje. En particular, para la búsqueda de hiperparámetros consideramos:
En términos del problema a resolver, no tenemos manera fácil de decidir cuál tipo de error es el más grave. Si trabajáramos para superhéroes, entonces no quisieramos que personajes son buenos cuando en realidad son malos, pero podríamos estar trabajando para supervillanos así que no haré esos supuestos, y se hará la búsqueda según f1_weighted, pero veremos los classification_scores para elección.
Cambiamos el score_func de SelectPercentile a chi2 para que vea dependencias no lineales, de manera mucho más veloz que mutual_info_classif, y aprovechando que las variables ya son no negativas.
feature_params = {"pipeline__columntransformer__bag_of_words__ngram_range": [(1, 1), (1, 2), (1, 3)],
"pipeline__columntransformer__bag_of_words__binary": [False, True],
"pipeline__selectpercentile__percentile": [20, 40, 60, 80],
"pipeline__selectpercentile__score_func": [chi2],
}
def grid_search_eval(model, model_params):
"""Calcula el mejor modelo con gridsearch, imprime su reporte de clasificación,
retorna el modelo y sus parámetros."""
pipeline = Pipeline(steps=[("pipeline", feature_pipeline), ("model", model)])
model_params = {f"model__{key}": val for key, val in model_params.items()}
grid = HalvingGridSearchCV(pipeline, feature_params | model_params,
cv=3, scoring="f1_weighted", random_state=0,
n_jobs=-1, min_resources="smallest", aggressive_elimination=True,
verbose=10,
)
best_model = grid.fit(X_train, y_train).best_estimator_
print(classification_report(y_test, best_model.predict(X_test)))
return best_model, grid.best_params_
cnb, cnb_params = grid_search_eval(ComplementNB(),
{"alpha": [0.5, 1.],
"norm": [True, False]
}
)
n_iterations: 5
n_required_iterations: 5
n_possible_iterations: 4
min_resources_: 18
max_resources_: 963
aggressive_elimination: True
factor: 3
----------
iter: 0
n_candidates: 96
n_resources: 18
Fitting 3 folds for each of 96 candidates, totalling 288 fits
----------
iter: 1
n_candidates: 32
n_resources: 18
Fitting 3 folds for each of 32 candidates, totalling 96 fits
----------
iter: 2
n_candidates: 11
n_resources: 54
Fitting 3 folds for each of 11 candidates, totalling 33 fits
----------
iter: 3
n_candidates: 4
n_resources: 162
Fitting 3 folds for each of 4 candidates, totalling 12 fits
----------
iter: 4
n_candidates: 2
n_resources: 486
Fitting 3 folds for each of 2 candidates, totalling 6 fits
precision recall f1-score support
Bad 0.55 0.54 0.54 108
Good 0.72 0.76 0.74 186
Neutral 0.30 0.21 0.25 28
accuracy 0.64 322
macro avg 0.52 0.50 0.51 322
weighted avg 0.63 0.64 0.63 322
En este punto, vemos que sí este clasificador le gana al Dummy en todo aspecto, pero existe un trade-off con respecto a MultinomialNB, donde se gana mejores puntajes para discriminar a personajes neutrales y malos, al costo de puntaje para personajes buenos. Sin embargo, los puntajes en general mejoran bastante, en especial en la clase Neutral.
rescale_svc = make_pipeline(MaxAbsScaler(),
SVC(random_state=0,
class_weight="balanced",
)
)
svc, svc_params = grid_search_eval(rescale_svc,
{"svc__kernel": ["linear", "rbf"],
"svc__C": [.5, 1.]
}
)
n_iterations: 5
n_required_iterations: 5
n_possible_iterations: 4
min_resources_: 18
max_resources_: 963
aggressive_elimination: True
factor: 3
----------
iter: 0
n_candidates: 96
n_resources: 18
Fitting 3 folds for each of 96 candidates, totalling 288 fits
----------
iter: 1
n_candidates: 32
n_resources: 18
Fitting 3 folds for each of 32 candidates, totalling 96 fits
----------
iter: 2
n_candidates: 11
n_resources: 54
Fitting 3 folds for each of 11 candidates, totalling 33 fits
----------
iter: 3
n_candidates: 4
n_resources: 162
Fitting 3 folds for each of 4 candidates, totalling 12 fits
----------
iter: 4
n_candidates: 2
n_resources: 486
Fitting 3 folds for each of 2 candidates, totalling 6 fits
precision recall f1-score support
Bad 0.61 0.39 0.47 108
Good 0.67 0.89 0.76 186
Neutral 0.17 0.04 0.06 28
accuracy 0.65 322
macro avg 0.48 0.44 0.43 322
weighted avg 0.60 0.65 0.60 322
Acá vemos que se empeora el f1-score tanto en los malos como los buenos, ligeramente empeorando el modelo con respecto a ComplementNB, pero además este modelo no lidia bien con el desbalance, sin determinar correctamente cuando son neutrales. Su desempeño general aún así es mejor que el de MultinomialNB.
trees, tree_params = grid_search_eval(ExtraTreesClassifier(random_state=0,
class_weight="balanced_subsample",
bootstrap=True,
),
{"max_features": ["sqrt", None],
"max_samples": [.75, 1.]
}
)
n_iterations: 5
n_required_iterations: 5
n_possible_iterations: 4
min_resources_: 18
max_resources_: 963
aggressive_elimination: True
factor: 3
----------
iter: 0
n_candidates: 96
n_resources: 18
Fitting 3 folds for each of 96 candidates, totalling 288 fits
----------
iter: 1
n_candidates: 32
n_resources: 18
Fitting 3 folds for each of 32 candidates, totalling 96 fits
----------
iter: 2
n_candidates: 11
n_resources: 54
Fitting 3 folds for each of 11 candidates, totalling 33 fits
----------
iter: 3
n_candidates: 4
n_resources: 162
Fitting 3 folds for each of 4 candidates, totalling 12 fits
----------
iter: 4
n_candidates: 2
n_resources: 486
Fitting 3 folds for each of 2 candidates, totalling 6 fits
precision recall f1-score support
Bad 0.62 0.42 0.50 108
Good 0.68 0.91 0.78 186
Neutral 0.00 0.00 0.00 28
accuracy 0.66 322
macro avg 0.43 0.44 0.43 322
weighted avg 0.60 0.66 0.62 322
Este clasificador nunca predijo que uno fuera Neutral, así que no ldiio bien con el desbalance. Si bien es mejor en discriminar a los buenos, el desempeño general sigue siendo ligeramente peor que ComplementNB
Nos quedamos con ComplementNB por tener un poco más de desempeño en mucho menos tiempo de entrenamiento. sklearn lo recomienda en la guía de Naïve Bayes, y tuvo efectivamente el mejor desempeño. Veamos los parámetros que fueron elegidos.
cnb_params
{'model__alpha': 0.5,
'model__norm': False,
'pipeline__columntransformer__bag_of_words__binary': False,
'pipeline__columntransformer__bag_of_words__ngram_range': (1, 1),
'pipeline__selectpercentile__percentile': 80,
'pipeline__selectpercentile__score_func': <function sklearn.feature_selection._univariate_selection.chi2(X, y)>}
Veamos las características más importantes según este modelo.
cnb.fit(X, y) # Re entrenando con todos los datos
final_feature_transformer = cnb.named_steps["pipeline"]
final_features = final_feature_transformer.transform(X)
pd.DataFrame(final_features.toarray(), columns=final_feature_transformer.get_feature_names_out())
| score_scaler__strength_score | score_scaler__speed_score | score_scaler__durability_score | score_scaler__power_score | score_scaler__combat_score | bag_of_words__! | bag_of_words__# | bag_of_words__$ | bag_of_words__& | bag_of_words__' | ... | bag_of_words__— | bag_of_words__‘ | bag_of_words__’ | bag_of_words__“ | bag_of_words__” | bag_of_words__アーカード | bag_of_words__駄犬 | bag_of_words__juggernaut | bag_of_words__� | bag_of_words__�kick� | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.3 | 0.60 | 0.60 | 0.40 | 0.70 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 1.0 | 0.80 | 1.00 | 1.00 | 0.80 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.5 | 0.55 | 0.45 | 1.00 | 0.55 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.1 | 0.25 | 0.40 | 0.30 | 0.50 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.4 | 0.45 | 0.55 | 0.55 | 0.85 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1280 | 0.1 | 0.25 | 0.30 | 1.00 | 0.55 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1281 | 1.0 | 1.00 | 1.00 | 1.00 | 0.80 | 1.0 | 0.0 | 0.0 | 0.0 | 8.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1282 | 0.5 | 1.00 | 0.75 | 1.00 | 0.80 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1283 | 0.1 | 1.00 | 0.30 | 1.00 | 0.30 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1284 | 0.8 | 0.75 | 0.95 | 0.80 | 0.50 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
1285 rows × 18229 columns
importance_frame = pd.DataFrame(index=final_feature_transformer.get_feature_names_out())
for alignment, importance in zip(cnb.named_steps['model'].classes_, cnb.named_steps['model'].feature_log_prob_):
importance_frame[alignment] = importance #pd.Series(importance, )
importance_frame
| Bad | Good | Neutral | |
|---|---|---|---|
| score_scaler__strength_score | 7.288231 | 6.691373 | 7.125317 |
| score_scaler__speed_score | 7.068273 | 6.593954 | 6.960767 |
| score_scaler__durability_score | 6.898151 | 6.379045 | 6.764895 |
| score_scaler__power_score | 6.709533 | 6.216074 | 6.583681 |
| score_scaler__combat_score | 6.671396 | 6.230883 | 6.563095 |
| ... | ... | ... | ... |
| bag_of_words__アーカード | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__駄犬 | 13.732044 | 11.251337 | 12.309682 |
| bag_of_words__juggernaut | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__� | 9.441585 | 9.147203 | 9.628660 |
| bag_of_words__�kick� | 12.122606 | 12.860775 | 12.309682 |
18229 rows × 3 columns
Veamos las más altas de cada clase
importance_frame[importance_frame.Bad == importance_frame.Bad.max()]
| Bad | Good | Neutral | |
|---|---|---|---|
| bag_of_words__'29 | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__'a | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__'autopsi | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__'birth | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__'bloodtox | 13.732044 | 11.762163 | 12.820508 |
| ... | ... | ... | ... |
| bag_of_words__ε | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__تاليا | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__アーカード | 13.732044 | 11.762163 | 12.820508 |
| bag_of_words__駄犬 | 13.732044 | 11.251337 | 12.309682 |
| bag_of_words__juggernaut | 13.732044 | 11.762163 | 12.820508 |
2819 rows × 3 columns
importance_frame[importance_frame.Good == importance_frame.Good.max()]
| Bad | Good | Neutral | |
|---|---|---|---|
| bag_of_words__'after | 12.633432 | 12.860775 | 12.820508 |
| bag_of_words__'alpha | 12.633432 | 12.860775 | 12.820508 |
| bag_of_words__'arm | 12.633432 | 12.860775 | 12.820508 |
| bag_of_words__'arti | 12.633432 | 12.860775 | 12.820508 |
| bag_of_words__'bad | 12.633432 | 12.860775 | 12.820508 |
| ... | ... | ... | ... |
| bag_of_words__· | 11.534819 | 12.860775 | 11.721895 |
| bag_of_words__ñoldor | 9.688993 | 12.860775 | 9.876069 |
| bag_of_words__σ | 12.122606 | 12.860775 | 12.309682 |
| bag_of_words__نيسا | 12.122606 | 12.860775 | 12.309682 |
| bag_of_words__�kick� | 12.122606 | 12.860775 | 12.309682 |
7397 rows × 3 columns
importance_frame[importance_frame.Neutral == importance_frame.Neutral.max()]
| Bad | Good | Neutral | |
|---|---|---|---|
| bag_of_words__'convinc | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__'last | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__'puppet | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__'re-educ | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__'replac | 12.633432 | 11.762163 | 13.91912 |
| ... | ... | ... | ... |
| bag_of_words__zoiray | 11.534819 | 10.663550 | 13.91912 |
| bag_of_words__الساحر | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__الغول | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__سراب | 12.633432 | 11.762163 | 13.91912 |
| bag_of_words__ | 12.122606 | 11.251337 | 13.91912 |
874 rows × 3 columns

LLego el momento de predecir
Vergil, Gorilla Girl y Batcow
Nota: Recuerde que pueden existir campos vacios en history_text, por lo que se les recomienda borrar los nan.
Respuesta:
to_predict = df_comics_no_label.dropna(subset="history_text")
to_predict = to_predict[to_predict.name.isin({"Vergil", "Gorilla Girl", "Batcow"})].drop_duplicates()
to_predict
| Unnamed: 0 | name | real_name | full_name | overall_score | history_text | powers_text | intelligence_score | strength_score | speed_score | ... | has_flight | has_accelerated_healing | has_weapons_master | has_intelligence | has_reflexes | has_super_speed | has_durability | has_stamina | has_agility | has_super_strength | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 122 | Batcow | None | None | 3 | Bat-Cow was originally a cow that was found by... | NaN | 70 | 10 | 25 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 40 | 529 | Gorilla Girl | Fahnbullah Eddy | Fahnbullah Eddy | 7 | A carnival performer with the ability to turn ... | Gorilla Girl can transform into a talking gori... | 90 | 35 | 60 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| 78 | 1368 | Vergil | Vergil Sparda | NaN | 16 | Vergil, later also known as Nelo Angelo, is on... | NaN | 90 | 75 | 95 | ... | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
3 rows × 82 columns
Para esta sección, reentrenamos el modelo en todos los datos
predictions = cnb.predict(to_predict)
pd.Series(predictions, index=to_predict.name)
name Batcow Good Gorilla Girl Bad Vergil Neutral dtype: object
Aprovecho de incluir mi tier list de los mejores candidatos para reemplazar a Batman en el caso de su muerte, con BatCow sólidamente en A tier. ¿El mejor? El mismísimo Batman.


 Created in
Created in